Regular 性能优化的几点建议
本文旨在用 20% 的精力解决使用Regular过程中 80% 的性能问题.
这里大部分是关于脏检查的性能优化,不了解的可以先看下《Regular脏检查介绍》
首先,我们可以用一个简化后的公式来描述Regular的单次脏检查的复杂度
N·logN · M · T
其中
- N : 代表组件深度
- M : 代表组件平均监听器数量
- T : 代表单个Watcher的检查时间
这样问题就落在了如何降低这三个因子了
1. 降低N —— 组件层级
这层是收益最高的方案,因为影响因子是 N·logN.
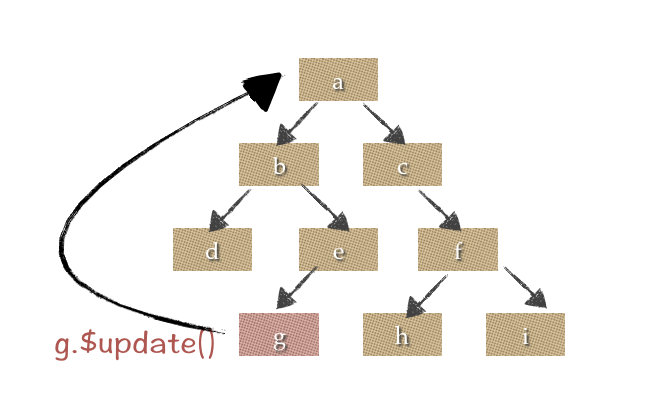
以上图为例,叶子节点进行$update()时,会首先找到DigestRoot (默认情况下,即顶层使用 new 创建的组件),再层层向下进行组件的$digest()检查,在目前组件抽象较细致的开发习惯下,很容易产生10多层的组件深度,适当控制下digest深度可以得到可观的性能提升。
注 : 这个digest flow设计是为了避免产生网状更新链
1.1. 方案1. 使用isolate 控制digest深度
第一个方式即使用isolate属性控制组件的数据流向,如<b isoalte /> 这样,在第一次初始化后,b组件就不再与a组件有任何数据绑定关系
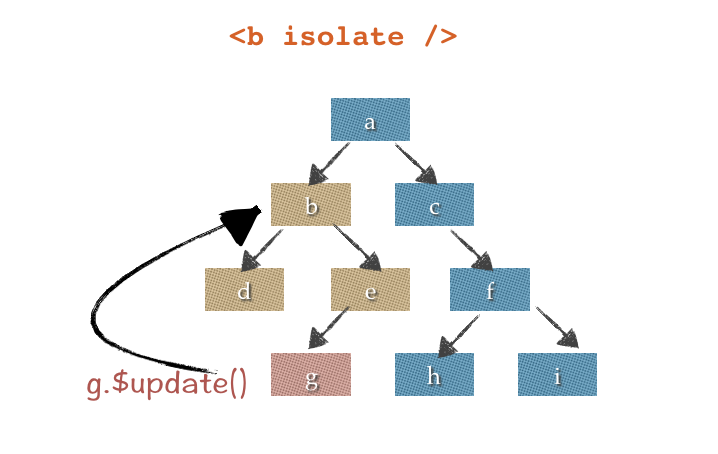
如图所示,b组件此时就会成为g组件的实际DigestRoot。b组件内部的$update不会再会冒泡到外层
但这种方式同时让a的数据变更无法传达到b组件极其内部,如下图所示
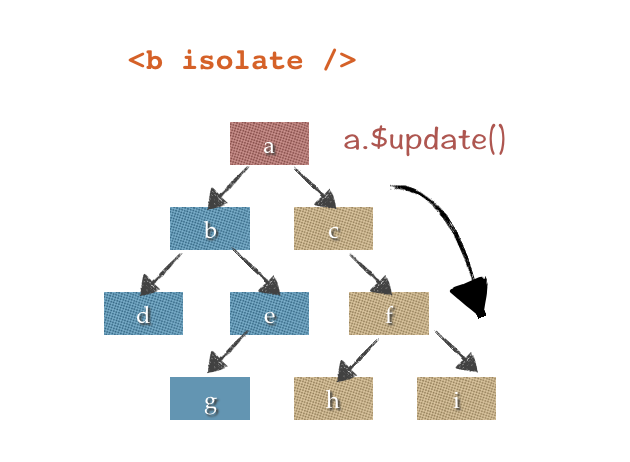
如果需要实现a->b的单向传导,可以设置isolate=1
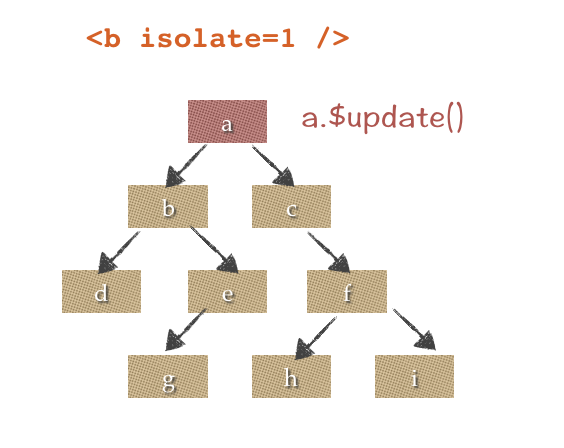
isolate = 1 实际就形成了组件的单向数据流
1.2. 方案2. 合理抽象组件
除了通过isolate手动控制更新树的深度之外,我们直接减小组件深度当然也可以。 但这似乎与React等框架推崇的方式相悖,其实不然。
过度抽象的组件,除了引入使用负担和增加组件层级外,无法带来直观的收益。 抽象记得要基于复用的前提,没有复用前提的组件抽象,除了让你的文件夹变得更复杂外,毫无益处。 当然它可以给你带来好看的组件结构图 :)
2. 降低M: 平均监听者数量
在Dirty-Check Loop中,在每个组件节点上都会经历$digest阶段: 遍历监听者数组,检查数据是否发生变更。
2.1. 方案1. 升级到v0.5.2版本以上
首先将上面的公式再简化,并拓展到 一轮完整的脏检查Dirty-Check Loop ,可以用下面的公式来表示
2.2. ` K·P·T`
其中
- K: 脏检查稳定性检测轮数 (1~30次不等,30次仍不稳定将抛出错误)
- P:digest影响到的所有监听器
- T: 单个监听器的消耗时间
在Github: 0.5.2版本,有一个优化就是讲监听器分为了 稳定监听器(stable) 和 不稳定监听器(unstable)
不稳定的监听器即具有Side Effect,比如
this.$watch('firstName', (firstName)=>{
this.data.nickname = firstName + '先生'
})
当firstName改变时,nickname也会随之改变,所以为了确保不出错,框架会检测多轮直到这类监听表达式不再变化
稳定的监听器就是一些没有Side Effect的监听比如大部分内置的监听(文本插值、r-html、属性插值等), 这类监听处理逻辑只有读操作,而没有写操作。其实只需要检测一次即可
这样公式就修改为了
2.3. ` K·P1·T + P2·T`
其中 P1+P2 = P , P2 为Stable监听器, P1为非稳定。不要小看这个优化,由于内部监听器中, P2的比例很高(超过80%)所以在K>1的情况下,可以带来比较大的提升。
除此之外,你同时也可以自己主动来标记哪个监听器是属于stable
this.$watch('title', (title)=>{
this.$refs.top.innerText = title
}, {stable: true})
2.4. 2. 使用一次绑定表达式@(expression)
除非明确了不再对某个监听感兴趣,通过 一次绑定表达式 来提升性能其实并不是特别关键,但如果这个表达式正好在一个list循环中,那控制的收益会比较大,比如
{#list list as item by item_index}
<some-component list={@(item.list)} />
{/list}
如果这个列表有100项,那可以直接减少100个对item.list绑定(何况大部分情况都不止一个属性传入), 属于操作少收益大。
3. 降低T: 单个监听器的平均消耗时间
其实每个表达式比如user.firstName + '-' + user.lastName 需要判断变化的开销各不相同,我们只需要针对高开销的监听器进行控制即可达到效果。
3.1. 1. 尽可能带上list语句的by描述
list是最容易产生性能瓶颈的部分,下面做下简单说明
默认情况下,Regular使用的莱文斯坦编辑距离(Levenshtein Distance), 别被吓到了,实际上wiki百科等资源上都有完成的伪代码描述, 是个简单的常用算法。
它的优点是,不需额外标记,就可以找到尽可能少的步骤从一个字符串过渡到另一个(但并不保证相同值一定被保留), 数组同理. 这样映射到框架内部,就可以以尽可能少的步骤来变更DOM了,相信大家都知道DOM开销很大了。
但是它的时间复杂度是O(n^2) ,在大列表下会带来显著的性能开销, 甚至完全超过DOM更新的开销。
所以在Regular v0.3的某个版本引入了by的用法, 例如
{#list items as item by item_index}
<li>{item.name}</li>
{/list}
顾名思义,新旧列表按顺序其item_index是不会变化的,即0,1,2... . 所以列表更新时,不会尝试去销毁重建,而是直接更新内部的值. 这种更新方式,内部的diff复杂度是 O(n), 属于极大的优化了性能.而且在DOM更新上比LS算法模式更轻量
这样用by item_index其实也带来一个问题,就是虽然循环对应的值改变了,但内部组件是不会重建的,即config、init不会被触发。
理论上 by 关键词之后可以接任意表达式,但是在之前版本是不生效的 (详情看#90 regularJS的track by没起作用) .
这个问题在最新版本已经被修复, 即你可以更精确的控制,是否要复用某一个项对应结构(内部组件是不会重建的,即config、init不会被触发)
{#list items as item by item.id}
<li>{item.name}</li>
{/list}
举个例子,只要item.id ===0的项还在,那对应的DOM结构就确保不会被回收,只会进行更新操作. 这里的时间复杂度也是O(n), 但实际开销会比by item_index高不少。
3.2. 2. 升级到v0.5.2减少销毁时间
在之前的版本, Regular的模板内容在销毁时,内部会进行大量的splice操作导致了性能问题,在0.5.2版本进行优化,整体销毁时间有了 数倍的提升
4. 总结
从操作难易度和关键度上,主要是以下建议
- 升级到Regular最新版本(也方便你使用最新的SSR、跨组件通信等特性),至少也是v0.5.2来整体提高性能(这个版本还做了不少别的性能优化)
- list记得使用by语句,特别是
by item_index(item_index取决于你的命名) - 组件通过isolate来控制digest深度